
I. Unités considérées en lecture
II. Accès au lexique et reconnaissance des mots
III. Processus automatiques et contrôlés
Le but de la recherche sur la reconnaissance visuelle de mots est de comprendre quels mécanismes cognitifs sous-tendent la compréhension rapide et relativement aisée de mots en lecture, comment sont acquises ces capacités et quelles conséquences peut avoir une lésion cérébrale sur ces processus.
Les modèles de lecture présentent les différentes étapes nécessaires au traitement de l’information. Ceux que nous présenterons ici tentent de rendre compte des effets que peuvent jouer la fréquence (Healy & Drewnowski, 1977; Laberge & Samuels, 1974 ; Becker, 1979), le contexte (Posner & Snyder, 1975 ; Stanovitch & West, 1981 ; Rumelhart, 1977 ; Rumelhart & McClelland, 1982) et l’attention (Laberge et Samuels, 1974) sur les processus de reconnaissance de mots.
Lire suppose la mise en relation d’un signifiant et d’un signifié. Cette relation étant purement arbitraire, l’accès au sens nécessite un codage préalable des formes lexicales. Le lecteur doit, dans un délai très bref, faire en sorte que le mot sélectionné dans le lexique mental corresponde au mot qui lui est donné à lire.
Un texte écrit peut être analysé selon cinq niveaux distincts, ces derniers étant fonction des unités en présence, à savoir : les lettres, les groupes de lettres, les syntagmes, les propositions et les phrases
Le niveau d’identification d’une unité peut être contrôlé par le biais d’une tâche impliquant que le sujet entoure chaque occurrence d’une cible donnée au sein d’un texte (Corcoran, 1966 ; Healy, 1976 ; Healy & Drewnowski 1977…) Le plus haut niveau pouvant être atteint dépend non seulement de la compétence en lecture du sujet (Gibson, 1971, Laberge & Samuels, 1974) mais aussi de la tâche proposée (Estes, 1975) et de la nature du stimulus : un mot grammatical est lu en termes d’unités plus larges que le mot (Healy & Drewnowski, 1977).
Certains auteurs, comme Gibson (1971), considèrent que le lecteur ne peut accéder aux différents niveaux que de manière séquentielle, c’est-à-dire qu’il ne peut atteindre un niveau supérieur qu’à la condition d’avoir terminé le traitement à un niveau inférieur. Le modèle de traitement proposé par Healy et Drewnowski (1977) suppose, au contraire, que les lecteurs traitent les stimuli à la fois au plus haut niveau (la phrase) et au plus bas niveau (la lettre) et ce, de manière parallèle.
L’écrit étant une transcription du langage oral, la question se pose de savoir s’il est nécessaire de traduire l’écrit en son afin d’accéder à la compréhension ou si seuls les signes graphiques (et non leur valeur phonologique) permettent l’accès au sens.
2. 1. L'hypothèse d'un accès direct
Cette hypothèse postule que l’information phonologique ne joue aucun rôle dans la lecture silencieuse. Autrement dit, le lecteur n’a nul besoin de convertir les informations graphiques en son (représentation mentale de la prononciation du mot) pour accéder au sens, la configuration graphique lui suffit pour accéder directement à sa signification en mémoire. Les mécanismes de reconnaissance des mots supposent donc une représentation orthographique en mémoire, laquelle permet, par un phénomène dit d’ « adressage », de recouvrer les informations relatives au sens et à la prononciation (en vue d’une vocalisation éventuelle) du mot reconnu.
Utiliser l’information visuelle semble plus « économique » du point de vue des activités cognitives impliquées dans la mesure où l’écrit est directement converti en sens ; l’usage de la phonologie implique, au contraire, une étape supplémentaire : l’écrit est converti en son avant d’être traduit en sens. Cependant, l’omission fréquente de e muets (Corcoran, 1966) ainsi que les retards de détection de lettres causés par des confusions acoustiques (Krueger, 1970) doivent nous faire réfuter cette hypothèse dès lors qu’ils sous-tendent la présence d’unités phonologiques. En effet, ces erreurs et ces retards de détection semblent indiquer que les lecteurs cherchent plus l’image acoustique que l’image visuelle de la cible qu’ils ont à localiser.
2. 2. L'hypothèse d'une médiation phonologique:
Une hypothèse centrale aux études portant sur les modes d’accès au lexique mental est l’existence de processus de conversion grapho-phonologiques capables de générer une représentation phonologique à partir d’une séquence de lettres écrites. Autrement dit, le lecteur doit traduire le mot qu’il voit en « sons » avant de lui assigner une signification. L’un des principaux arguments en faveur de cette hypothèse est le fait que tout lecteur puisse lire un mot jamais rencontré à l’écrit auparavant et ce, en associant au mot écrit une représentation mentale spécifiant comment le mot s’entend et se prononce. Au début des années 70, des auteurs ont considéré la conversion phonologique de l’information graphique comme indispensable à l’identification des mots (Gough, 1972 ; Rubenstein, Lewis et Rubenstein, 1971). La première étape consisterait en la construction d’une représentation phonologique du mot par l’intermédiaire d’un ensemble de règles d’association entre unités orthographiques et unités phonologiques. Dans un second temps, cette représentation phonologique serait utilisée pour accéder aux représentations lexicales. L’appariement de la représentation phonologique assemblée du mot (association entre unité orthographique et phonologique) avec sa représentation phonologique stockée dans le lexique mental conduirait à l’identification du mot, c’est-à-dire à la récupération des propriétés sémantiques (et syntaxiques).
De nombreuses expériences portant sur les effets d’amorce (présentation d’un mot, ou d’un non-mot dans certains cas, avant celle du mot cible) corroborent l’hypothèse d’un « codage phonologique ». La technique d’amorçage permet de faire varier la nature de la relation entre amorce et cible. Si la cible est par exemple le mot BOCAL, on peut présenter comme amorce soit BOKAL (qui est relié phonologiquement à la cible) soit BOFAL, qui n’est relié à la cible que du point de vue graphique (là encore, une seule lettre diffère mais la prononciation est différente), soit un autre mot (ou non-mot) sans aucun lien (par exemple RALIN). L’expérience montre que la présence d’une amorce liée à la cible facilite l’identification, et que cette facilitation est plus grande dans le premier cas (amorçage phonologique et graphémique) que dans le second (amorçage graphémique seulement).
Notre capacité à identifier les mots homophones tels que « champ » et « chant », « thym » et « teint » qui ne peuvent être différentiés qu’en fonction de l’information orthographique (Brewer, 1972 ; Massaro, 1975), conduisent toutefois à réfuter l’idée d’une médiation phonologique obligatoire et à accepter l’idée que l’identification des mots puisse aussi reposer sur l’information orthographique (Rubenstein et al. ,1971 ; Gough, 1972 ; Brewer, 1972 ; Kavanagh et Mattingly, 1972). Un second obstacle à l’hypothèse d’une médiation phonologique obligatoire est en rapport avec notre habileté à comprendre facilement des mots tels que « femme », « second », « oignon » ou « écho » qui sont irréguliers en ce qui concerne les correspondances entre graphie et phonie. Or, les résultats expérimentaux obtenus par Seidenberg, Waters, Barnes et Tanenhaus (1984) indiquent que, en anglais, l’identification des mots irréguliers fréquents (tel que « have ») est aussi rapide que celle des mots réguliers (tel que « gave »).
Ces constatations conduisent donc à envisager qu’il y a plusieurs « routes » possibles, fondées sur des codes de différentes natures (orthographique ou phonologique).
2. 3. La théorie des deux routes (Coltheart, 1978)
Le principe de base de cette théorie est que la reconnaissance des mots peut être réalisée selon deux « routes » différentes : visuelle et phonologique.
Si, la plupart du temps l’information orthographique est suffisante (l’accès direct), un codage issu de la deuxième route serait indispensable dans le cas de non-mot : la médiation phonologique est optionnelle. Selon cette théorie « dichotomique », l’accès lexical passerait soit par une route, soit par l’autre, mais pas par les deux. Les deux processus (accès direct et médiation phonologique) étant réalisés avec des vitesses différentes, c’est le plus rapide (l’accès direct) qui l’emporte en général, sauf lorsque les caractéristiques du stimulus l’empêchent d’aboutir (nom propre, mot inconnu ou mot rare).
Cet aspect dichotomique est aujourd’hui remis en question, notamment par Ferrand et Grainger (1995) dont les travaux reposent sur l’hypothèse générale qu’il y a activation des deux sources d’informations, orthographique et phonologique, lors de la lecture. Cette activation, à la fois automatique, irrépressible et très rapide, se produit avant tout traitement élaboré relatif à la signification des mots. Les deux sources d’informations joueraient chacune un rôle, de manière indépendante ; l’activation de l’information orthographique précédant celle de l’information phonologique.
Des unités autres que phonologiques ou visuelles peuvent toutefois exister : Goodman (1969) a montré que les sujets pouvaient, en lecture à haute voix, commettre des erreurs consistant à substituer des mots à d’autres mots sémantiquement proches et dire « Il se promène dans le bois » au lieu de « il se promène dans la forêt ». De telles substitutions supposent donc que, dans ce cas, l’unité de traitement est le contenu sémantique du mot.
2. 4. Modèle de la mémoire de travail (Baddeley, 1986)
Faisant le lien entre les informations phonologiques extraites du stimulus visuel et la mémoire de travail, le modèle élaboré à l’origine par Baddeley et Hitch 1974 (Voir Figure 1), puis développé par Baddeley en 1986, présente la mémoire de travail comme une structure tripartite comprenant un administrateur central (central executive) assisté de deux systèmes esclaves : la boucle phonologique (phonological loop) et le calepin visuo-spatial (visuo-spatial sketchpad).
L’administrateur central est la composante attentionnelle du système : il sélectionne, coordonne et contrôle les opérations de traitement. La boucle phonologique maintient l’information sous une forme phonologique, tandis que le calepin visuo-spatial la maintient sous un code imagé (le lecteur « visualise » l’action décrite par la phrase et la maintient en mémoire sous forme d’image mentale).
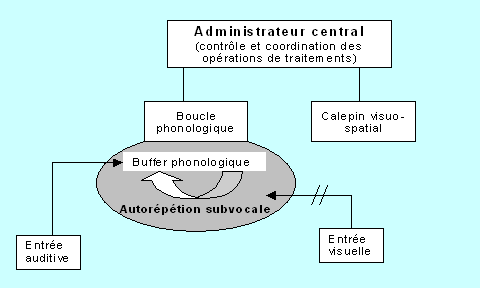
Figure 1. Modèle de la mémoire de travail proposé par Baddeley et Hitch
La boucle phonologique est un système mnésique comprenant une unité de stockage phonologique, où sont maintenues durant 2 secondes environ les informations phonologiques extraites du stimulus visuel (on parle de « mémoire tampon » ou buffer pour souligner son caractère passif) et un processus de contrôle articulatoire, chargé de rafraîchir les traces mnésiques des informations phonologiques par le biais d’un mécanisme d’autorépétition subvocale (reposant sur le langage intérieur). Ce processus permet en quelque sorte de « recycler » les informations avant qu’elles ne s’effacent du système de stockage phonologique. Afin d’illustrer ce mécanisme, imaginons la scène suivante : vous êtes à la caisse d’un magasin et vous comptez utiliser une carte de crédit dont vous ne vous servez que très rarement. Ne vous rappelant plus du code, vous attrapez le carnet sur lequel vous l’avez inscrit. Une fois lu, vous répétez mentalement ce code de manière cyclique afin de le garder en mémoire jusqu’à ce que vous l'ayez composer.
Le schéma ci-après (Figure 2) rend compte du rôle que le système de récapitulation articulatoire peut jouer dans le codage phonologique des informations verbales présentées en modalité visuelle. Celles-ci pourraient en effet transiter du système de stockage visuel au système de stockage phonologique via le recodage phonologique et la récapitulation articulatoire.
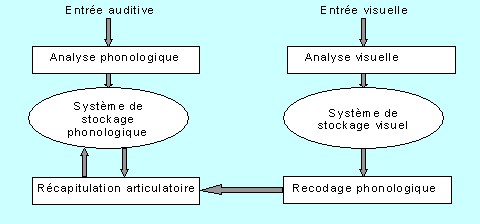
Figure 2. Modèle de la mémoire de travail de Baddeley, d’après Van Der Linden, 1991
L’existence de la boucle phonologique[1] repose sur trois observations principales : l’effet de similarité phonologique, l’effet de longueur du mot et l'effet de suppression articulatoire.
Une expérience menée en 1966 par Alan Baddeley a montré que des sujets avaient beaucoup plus de difficultés à se rappeler une suite d’items phonologiquement proches les uns des autres du type « tas, pas, bas, ras, mas » qu’une suite d’items pouvant présenter une ressemblance sémantique du type « grand, large, haut, gros, vaste ».
Ceci suggère que les sujets mémorisent plus les items en fonction de leur sonorité ou de leurs propriétés articulatoires qu'en fonction de leur sens. Etant donné que le rappel nécessite une distinction parmi les traces en mémoire, on peut supposer que des traces similaires seront plus difficiles à distinguer et produiront un niveau de rappel inférieur.
L’observation de meilleures performances sur les mots courts que sur les mots longs lors de tâches de rappel immédiat est un argument supplémentaire en faveur de l’existence de la boucle phonologique. Cet effet de longueur du mot laisse penser que la boucle articulatoire opère un recyclage plus lent de l’information sur les mots longs. Ce ralentissement du processus de recyclage aurait pour conséquence une disparition plus rapide des informations dans le stock phonologique (rappelons qu’au-delà de deux secondes l’information phonologique disparaît si elle n’est pas réactivée par le processus de contrôle articulatoire).
Le fait qu’à longueurs égales (même nombre de syllabes), les mots se prononçant rapidement (ang. « Wicket, bishop ») sont mieux rappelés que ceux se prononcer lentement (comme « Friday» ou «harpoon » qui comportent des voyelles longues), valide également l’hypothèse d’un codage phonologique.
La suppression articulatoire renvoie à une technique dans laquelle, lors d’une tâche de mémoire à court terme, on demande au sujet d’articuler un matériel verbal itératif (bla bla bla….). On suppose que la chute des performances observée est due au fait que cette procédure « occupe » le système responsable du mécanisme de rafraîchissement : l’information n’étant plus rafraîchie, elle se dégrade rapidement.
Le lexique mental pourrait être défini, par analogie, comme un dictionnaire interne où figureraient aussi bien les mots de la langue que leurs propriétés orthographiques, phonologiques, syntaxiques et sémantiques. Etudier les processus d’accès au lexique consiste donc à déterminer comment le lecteur accède à ces propriétés à partir du code du stimulus (graphique ou phonologique).
En psychologie cognitive, le débat sur la reconnaissance des mots est traversé par une controverse théorique fondamentale sur la modularité de l’esprit. Les théories modulaires (Fodor, 1983 ; Swinney, 1979) conduisent à rejeter de manière radicale le rôle du contexte alors que l’approche interactive (Rumelhart, 1977 ; Rumelhart & McClelland, 1982, Stanovitch & West, 1981) considère, au contraire, que le contexte influence le processus de reconnaissance de mot.
1. 1. Conception modulaire
Selon l’approche modulariste, l’activité cognitive est assurée par des modules spécialisés qui effectuent des traitements à un niveau donné sans que ces traitements soient en rien influencé par les traitements des autres modules de même niveau. Pour les tenants de cette théorie, tel Fodor (1983), la compréhension du langage est une activité modulaire. Un module prend en compte le résultat des traitements réalisés en amont (identification des lettres) ; il rend le résultat de ses propres traitements au module situé en aval (l’interprétation sémantique suit l’identification du mot) mais il n’y a pas de possibilité de « retour » : l’accès lexical est insensible au traitement sémantique de la phrase qui n’interviendrait qu’après la reconnaissance du mot, à un niveau post-lexical, lors d’un processus tardif d’intégration du mot dans la phrase. Le contexte est supposé n’agir qu’au niveau de l’interprétation, et non au niveau de la reconnaissance des éléments du langage.
Modèle de Forster: Pour Forster (1979), la reconnaissance d’un mot implique deux processus : l’accès au lexique (qui en lecture se fait par le biais d’un code orthographique) et la vérification post-accès (voir Figure 4).
Pour qu’un lecteur puisse avoir accès aux informations lexicales, deux opérations préalables doivent avoir été effectuées : la construction d’un code orthographique et la sélection d’un code d’accès.
Construction d’un code orthographique. Cette première étape consiste en l’extraction des traits formels pertinents du mot lu, c’est-à-dire en l’extraction des caractéristiques graphiques permettant d’opposer entre elles les lettres constitutives d’un mot (voir Figure ). Le trait « barre verticale » permet, par exemple, d’opposer les lettres L et S mais ce trait n’est plus pertinent lorsqu’il s’agit de distinguer L de i (dans ce cas là, le « point » du i est le trait pertinent).

Figure 3. Extraction des traits formels pertinents
Sélection d’un code d’accès. Après construction, le code du mot est comparé à l’ensemble des codes contenus dans le fichier d’accès orthographique. Le code sélectionné au sein de ce fichier agit dès lors comme un « pointeur » et permet d’accéder à l’information lexicale contenue dans le fichier central.
La vérification post-accès consiste en la comparaison du mot sélectionné (assorti de toutes les informations orthographiques, phonologiques, syntaxiques et sémantiques qui lui sont associées) avec le stimulus visuel proposé.
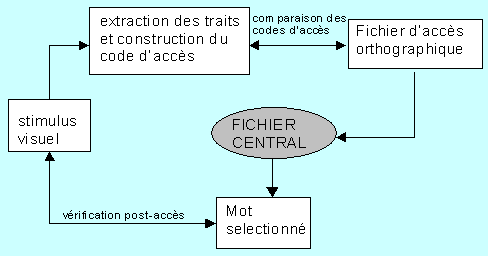
Figure 4. Conception modulaire de l'accès au lexique selon Forster
Dans ce cadre théorique, le lecteur traite une suite de lettres et non une unité de signification (un mot) afin de déterminer à quel élément de son lexique mental cette suite de lettres correspond. Comme nous allons le voir, ce point de vue n’est pas celui des tenants de l’interactivité.
1. 2. Conception interactive
Afin de rendre compte des effets que peut jouer le contexte lors de la reconnaissance d’un mot, Rumelhart (1977) propose un modèle interactif de lecture indiquant les différentes étapes nécessaires au traitement d’un syntagme nominal. Selon l’auteur, le rôle joué par le contexte pourrait être observé au cours d’une expérience consistant à présenter, par exemple, l’image d’une voiture sillonnant une route de montagne à proximité d’un lac et de faire suivre cette image par la présentation, au tachistoscope, d’un syntagme nominal que le lecteur saurait en rapport avec l’image proposée (du type « un lac », « une voiture »). La tâche du sujet serait alors de dire à quel élément de l’image le syntagme, brièvement proposé, fait référence.
Dans ce modèle, la première étape du traitement consiste à extraire des lettres du stimulus visuel les traits formels pertinents (barre ascendante ou descendante, forme arrondie…). C’est sur la base de ces derniers et à partir des propres connaissances du lecteur que le « synthétiseur de forme » élaborera les premières hypothèses d’ordres orthographique, lexical, syntaxique et sémantique. Toutes ces hypothèses seront ensuite confrontées les unes aux autres au sein d’un processeur central à capacité limitée : le centre des messages, lequel prend en compte la position de la lettre dans le mot ainsi que l’ensemble des hypothèses émises à chaque niveau (les traits distinctifs des lettres, les lettres, les groupes de lettres, le niveau lexical, le niveau syntaxique et le niveau sémantique). De cette confrontation naîtront d’autres hypothèses alors que certaines seront éliminées pour cause d'incompatibilité (par exemple, dans le schéma ci-après l’hypothèse « lac » émise au niveau sémantique conduit à éliminer l’hypothèse « bar » amenée au niveau lexical par le niveau syntaxique et par celui des groupes de lettres). Le processus s’achève lorsque la concordance de toutes les hypothèses émises à chaque niveau permet l’identification du groupe nominal présenté.
Afin d’illustrer le fonctionnement de ce modèle interactif, nous reprenons ci-dessous le schéma proposé par Rumelhart (voir .
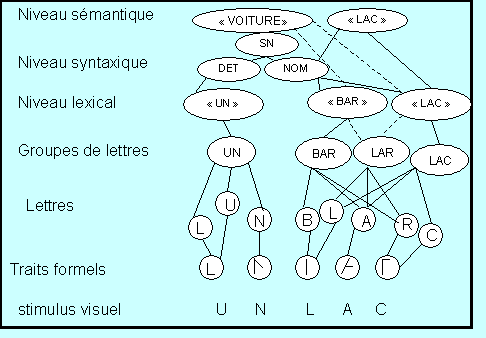
Figure 5. Conception interactive de l'accès lexical selon Rumelhart
Il y a interaction entre les niveaux : une hypothèse est à la fois reliée à ses « sœurs » de même niveau ainsi qu’à celles des niveaux immédiatement supérieur et inférieur. Les droites pleines indiquent les hypothèses activées tandis que celles en pointillés indiquent les hypothèses inhibées.
Le modèle d’activation interactif de Rumelhart et McClelland (1982) est la combinaison du modèle interactif de Rumelhart (1977) et des hypothèses émises par McClelland (1979) quant à la circulation de l’information au cours du traitement (voir Figure 6)
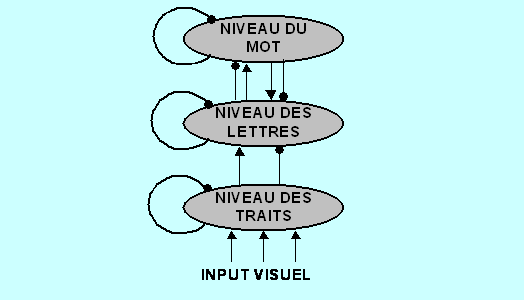
Figure 6. modèle d'activation interactif
Le modèle d’activation interactif rend à la fois compte des différents niveaux de traitement et de leurs interconnexions. (Les lignes se terminant par une flèche rendent compte de l’activation tandis que celles se terminant par un point indiquent les processus d’inhibition.)
Le degré d’activation dépend de la force de l’hypothèse, qui elle-même est fonction de l’existence et de la force des hypothèses voisines. Plus une hypothèse est forte, plus les autres hypothèses « concurrentes » seront inhibées.
Ex. Si l’hypothèse d’un T en première position d’un mot est fortement activée, les autres lettres possibles, à la même place, auront un très faible degré d’activation. Ceci fait que l’activation du mot « train » par exemple, qui coïncide avec l’hypothèse d’un T en première position, sera plus forte que celle d’autres mots ne coïncidant pas avec cette hypothèse.
Pour les auteurs de ce modèle, le contexte agirait sur les hypothèses émises au niveau des mots, en donnant plus de poids à celles coïncidant avec lui, voire en inhibant directement celles ne coïncidant pas avec lui.
Les mots grammaticaux, plus contraints sémantiquement que les mots lexicaux, c’est-à-dire plus « attendus », bénéficieraient donc davantage de cet effet contextuel et seraient de ce fait plus rapidement reconnus que les mots lexicaux.
La perception des mots est fortement liée à leur fréquence d’emploi dans la langue. Ainsi, des expériences basées sur l’enregistrement des mouvements oculaires ont montré que le seuil de perception est en rapport inverse avec la fréquence de chaque mot : les mots les plus fréquents sont perçus plus vite que les mots utilisés plus rarement. Nous proposons, afin d’illustrer ce phénomène, les modèles de lecture élaborés par Drewnowski & Healy (1977) et par Becker (1979).
2. 1. Modèle proposé par drewnowski & Healy (1977)
Comme nous l’avons dit plus haut, le fait de constater que des erreurs de détection de lettres puissent se produire, alors que les unités du mot sont présentes et donc aptes à être distinguées, amène Healy & Drewnowski à conclure à un traitement en parallèle des différents niveaux de lecture (lettres, groupes de lettres, mots, groupe de mots…). Le traitement aux niveaux supérieurs peut donc commencer avant que ne soient terminés tous les traitements des niveaux inférieurs.
Une fois une unité identifiée, le lecteur peut passer immédiatement à l’unité suivante sans nécessairement compléter le traitement aux niveaux inférieurs. Un sujet peut très bien, par exemple, identifier un mot et passer au suivant sans avoir identifier ni toutes les lettres, ni tous les groupes de lettres du mot. Par conséquent, plus le sujet sera capable d’identifier des unités à un niveau supérieur à celui de la cible donnée, plus le nombre d’erreurs de détection sera important et, inversement, si le sujet n’est capable de traiter que des unités de même niveau ou de niveau inférieur à celui de la cible, le nombre d’erreurs sera plus faible.
Si les lettres à l’intérieur des mots grammaticaux, et les mots grammaticaux eux-mêmes, ne sont pas détectées, cela signifie donc que ces derniers sont lus à des niveaux supérieurs à ceux des lettres et des mots.
2. 2. Modèle de vérification de Becker (1976)
Le modèle proposé par Becker (Becker 1976 ; Becker et Killion, 1977) prend en compte les effets du contexte. Ce modèle postule que l’accès au lexique s’effectue sur deux ensembles, un ensemble sensoriel (où les formes graphiques possibles sont ordonnées par ordre de fréquence) et un ensemble sémantique (constitué de mots contextuellement probables) dont la particularité est d’être construit avant que le mot soit reconnu dans l’ensemble sensoriel. Ainsi, la reconnaissance d’un mot s’effectue selon un processus de vérification qui peut agir sur l’ensemble sensoriel (en le parcourant de façon décroissante, du plus fréquent au moins fréquent) et sur l’ensemble sémantique (du plus « attendu » au moins « attendu ».)
Les « candidats » générés sont comparés à la représentation sensorielle du stimulus jusqu’à ce qu’une correspondance soit trouvée. L’identification du mot ne se fera que s’il y a adéquation. Si aucune correspondance n’est trouvée, le lecteur sélectionnera un autre candidat et commencera un autre cycle Test/Vérification.
Selon ce modèle, les mots très fréquents sont plus vite identifiés que les mots peu fréquents car ils ne nécessitent souvent qu’un seul cycle Test/Vérification.
Le fait d’avoir constaté des temps de lecture plus longs sur des mots inattendus fréquents que sur des mots attendus rares lors de tâches de masquage de lettres, a permis à Inhoff (1984) de montrer que les lecteurs se basent en premier lieu sur le contexte et non sur la forme graphique du mot pour dresser une liste d'entrées lexicales plausibles. Par contre, si le contexte immédiat est sans relation avec le mot cible, le lecteur devra élargir la palette des mots potentiels et, le contexte seul n’ayant pas permis de sélectionner le « bon mot », il devra recourir à un cycle de vérification à partir de la forme graphique du mot.
2. 3. Fréquence et Automatisation
Selon Laberge et Samuels (1974) la fréquence joue un rôle important dans le développement de l’automaticité de certains processus de traitement.
« (…) Repetition progressively frees the mind from attention to details, makes facil the total act, shortens the time, and reduce the extent to wich consciousness must concern itself with the process. » (HUEY, 1908, p.104)
Selon ces auteurs, plus un mot est fréquent dans la langue, plus l’association entre forme graphique et sens se fera de manière automatique .
Selon la perspective structurale adoptée à l’origine par le psychologue anglais Donald Broadbent, particulièrement connu pour ses recherches expérimentales sur l’attention, les informations sensorielles (traits formels des lettres) sont traitées automatiquement (sans attention) alors qu’un traitement complet du mot nécessite une deuxième étape qui, elle, fait appel à des ressources attentionnelles. Les travaux de Posner et Snyder (1975) vont profondément modifier cette représentation structurale du système de traitement en démontrant en particulier qu’un traitement peut être complet tout en étant largement automatique.
Pour ces auteurs en effet, traitements automatique et contrôlé ne constituent pas deux étapes d’un processus unique mais deux processus distincts, c’est-à-dire deux manières différentes de traiter l’information. Un mot employé ou lu très fréquemment par un lecteur fera l’objet d’un traitement automatique, c’est-à-dire d’un traitement rapide, ne nécessitant aucun effort attentionnel et pouvant être exécuté simultanément avec une activité contrôlée. Un mot peu fréquent par contre fera l’objet d’un traitement contrôlé, qui lui est plus lent, nécessite des efforts attentionnels et ne peut être exécuté en même temps qu’un autre processus contrôlé. Ainsi, un même mot, selon qu’il est utilisé fréquemment ou pas, peut faire l’objet de l’un ou l’autre mode de traitement. Le mot « psychopathologie » sera, par exemple, traité automatiquement par un psychologue (qui l’utilise fréquemment) mais de manière contrôlée par un non-spécialiste.
Nous avons vu que, selon une perspective modulaire, seules les propriétés formelles du mot permettent sa reconnaissance, alors qu’une approche interactive admet que le contexte puisse influencer le processus de reconnaissance de mot. Afin de départager ces deux conceptions, nous ferons mention de deux expériences menées, l’une par Swinney (1979), l’autre par Bedoin (1996), sur le traitement de phrases contenant un mot ambigu. Bien que les mots ambigus considérés ici appartiennent tous à la catégorie lexicale, nous pouvons supposer que ces expériences puissent nous renseigner sur les traitements dont font l’objet homonymes grammaticaux et lexicaux employés en contexte.
1. 1. Le contexte en tant qu'effet post-lexical (Swinney, 1979)
L’expérience menée consistait à proposer oralement des phrases comportant un terme lexicalement ambigu (c’est-à-dire un mot qui, employé seul, pourrait se prêter à deux interprétations) du type :
« En bousculant la table, il a fait tomber le verre. » (sens 1)
« En croquant la pomme, il a trouvé un ver. » (sens 2)
« De colère, il a jeté le ver / verre. » (sens neutre)
Ces phrases étaient accompagnées visuellement d’une suite de lettres pouvant être :
a) un mot sémantiquement associé au sens 1 (« vin »)
b) un mot sémantiquement associé au sens 2 (« terre »)
c) un mot neutre par rapport au mot ambigu oral (« livre »)
d) un pseudo-mot construit de telle sorte que l’agencement des lettres en groupes de lettres respecte les schémas de construction en termes de fréquence des mots de la langue.
Un moyen d'appréhender les processus de reconnaissance du point de vu de leur succession temporelle était de voir si des différences étaient constatées sur la tâche de décision lexicale (mot / non-mot) que le sujet devait accomplir sur le dernier mot de la phrase (le mot ambigu) selon que le stimulus visuel était présenté simultanément au mot oral ou de manière différée (3 syllabes après la fin du mot ambigu oral).
Les résultats ont montré une facilitation de la décision en présentation simultanée et ce, que le mot présenté visuellement soit ou non, sémantiquement associé au mot ambigu oral. En différé, par contre, il n’y a facilitation que dans le cas de « conformité » entre les deux items.
La conclusion de Swinney est que, lorsqu’un mot est présenté, tous les sens possibles sont d’abord automatiquement activés, sans pour autant être traités au plan sémantique. Dans un deuxième temps seulement le sens correspondant au contexte est sélectionné, ce qui correspond à des traitements post-lexicaux.
Cette expérience ne conduit pas à rejeter totalement le rôle du contexte mais considère qu’il ne participe pas immédiatement de la phase de reconnaissance du mot, n'intervenant qu'après un délai de quelques centaines de millisecondes. Ceci conduit donc à distinguer l’accès lexical (association d’une suite de lettres à un élément du lexique mental) et le traitement sémantique (attribution d’une signification en fonction du contexte). Ce postulat d’un effet post-lexical du contexte est toutefois loin de faire l’unanimité puisque d’autres expériences, dont celle mentionnée ci-après, ont montré que le contexte pouvait influer directement sur les processus de reconnaissance du mot et donc avoir un effet pré-lexical.
1. 2. Ajustement d'une fenêtre attentionnelle (Bedoin, 1996)
Bedoin (1996) pose l’hypothèse que le contexte sémantique d’une phrase puisse influer sur les processus de reconnaissance de mot par le biais du pré-ajustement d’une fenêtre attentionnelle. La tâche de décision lexicale que devaient accomplir les sujets sur le dernier mot d’une phrase (toujours un nom commun) semble en effet prouver d’une part que l’incohérence sémantique joue un rôle sur la décision lexicale (un mot attendu est plus vite reconnu qu’un mot inattendu) et, d’autre part, que le traitement du début d’une phrase sémantiquement contraignante du type « on enfonce un clou à coup de … » entraîne le pré-ajustement d’une fenêtre attentionnelle dont l’amplitude correspond à celle du mot attendu, à savoir les sept lettres du mot « marteau ». En attente d’un mot court, le traitement sémantique du début de la phrase conduit au pré-ajustement d’une fenêtre attentionnelle qu’il est nécessaire d’agrandir si le mot cible est long (ceci se traduit par des retards dans la décision lexicale). Le fait de proposer un mot court alors qu’un mot long est attendu n’entraîne par contre aucune opération de rétrécissement de la fenêtre attentionnelle.
L’ajustement d’une fenêtre attentionnelle n’est possible que lorsqu’il s’agit d’un mot familier (un mot rare n’est pas celui qui vient immédiatement à l’esprit lorsqu’il s’agit de compléter une phrase) très contraint par le contexte sémantique de la phrase. Or, les morphèmes grammaticaux remplissent ces deux conditions et il serait donc logique qu’ils soient plus vite reconnus que les mots lexicaux.
Plusieurs processus de traitement, doivent être accomplis durant le court moment que dure la lecture. Or, cette tâche serait irréalisable si tous ces processus demandaient autant d’attention les uns que les autres. En effet, nos capacités attentionnelles sont limitées et nous ne pouvons traiter plusieurs informations à la fois que parce que certains de ces traitements sont automatisés.
2. 1. Modèle de Laberge et Samuels (1974)
Le modèle proposé (voir Figure 7) décrit les principales étapes nécessaires à la transformation d’une forme orthographique en sens et montre le rôle des processus attentionnels qui peuvent (ou) non intervenir à chacune de ces étapes.
Avant d’accéder au sens (le niveau sémantique), le lecteur devra traiter le stimulus visuel à plusieurs niveaux : celui de la mémoire visuelle, de la mémoire phonologique, de la mémoire épisodique et celui de la mémoire sémantique.
Fonctionnement de la mémoire visuelle :
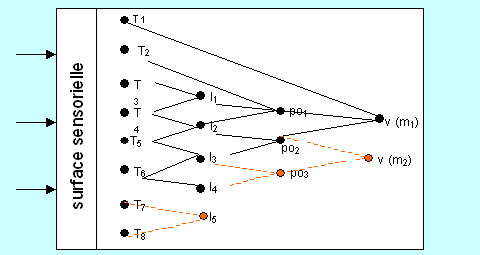
Figure 7. niveau de codage de l'information visuelle
La première information que donne un mot est d’abord analysée par des détecteurs, spécialisés dans l’extraction des traits formels pertinents, c’est-à-dire permettant de distinguer entre eux les différents stimuli visuels proposés. S’agissant des lettres, ces traits pertinents sont relatifs à la forme générale (general feature) et peuvent concerner les barres (descendante ou ascendante), les angles, les intersections, les courbures, les ouvertures…(un peu comme dans le modèle de Rumelhart vu plus haut)
Après avoir été analysées par les détecteurs de forme, les informations visuelles sont « traduites» en code-lettre. Ces codes activent les codes des patrons orthographiques (spelling paterns) qui, à leur tour, donnent les codes des mots. Les codes-mots peuvent parfois activer directement les codes des groupes de mots et certains traits formels peuvent de la même manière activer directement les codes des patrons orthographiques ou des mots.
Exemple : La barre descendante I est appareillée à la lettre q, laquelle est appareillée au patron orthographique qu, qui lui-même est appareillé au code du mot quête.
Lorsqu’un stimulus active un code, un signal est envoyé au centre d’attention, lequel peut attirer (ou pas) l’attention sur ce code. A quelque niveau que ce soit, le centre d’attention ne peut activer qu’un seul code du fait des limites du système attentionnel.
Chez l’apprenant, la construction du code de la lettre à partir des traits formels requiert une attention toute particulière alors que chez le lecteur « habile », ce processus est automatique. La répétition génère l’automaticité.
Les mémoires phonologiques et sémantiques fonctionnent et sont organisées de la même manière que la mémoire visuelle. La mémoire phonologique comprend les traits généraux ainsi que les codes phonologiques des lettres, des groupes vocaliques, des mots et des groupes de mots. La mémoire sémantique comporte, elle, les codes sémantiques des mots et des groupes de mots. Dans chacune de ces mémoires les codes sont organisés entre eux de manière hiérarchique (voir Figure 8).
La mémoire épisodique représente un chemin indirect permettant d’activer par exemple, par le biais de processus attentionnels, un code phonologique à partir d’un code phonétique. Les codes contenus dans la mémoire épisodique représentent les associations que peut faire un apprenant. L’enfant en situation d’apprentissage associera une lettre non familière à un son par des moyens mnémotechniques.
Plus tard dans l’apprentissage, un lien direct entre la mémoire visuelle et la mémoire phonologique peut être construit mais l’attention devra toujours être portée sur la lettre afin de parfaire l’association et de dégager le code phonologique de la lettre (c’est ce qu’indique la ligne en pointillés sur le schéma). Lorsque à force de pratique l’association sera automatique, l’attention pourra être portée sur un autre élément.
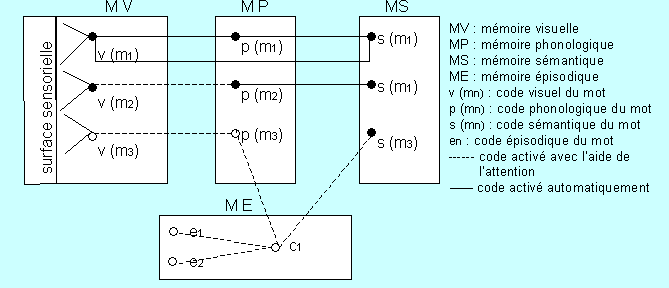
La Figure 9 présente non seulement les différentes étapes nécessaires au traitement d’un mot mais indique également quel rôle peut jouer l’attention dans l’activation des codes visuels, phonologiques ou sémantiques.

Figure 9. les différentes étapes nécessaires au traitement
Le schéma rend compte de différents modes de traitement :
- Possibilité 1 : (en rouge sur le schéma) Le stimulus graphique est automatiquement codé en un code-mot orthographique, lequel active automatiquement le code-mot sémantique. Ce traitement est souvent celui des mots très courants.
- Possibilité 2: (en bleu sur le schéma) Le stimulus graphique est automatiquement codé en un code-mot orthographique, lequel active automatiquement le code-mot phonologique p (m2). Ce code active ensuite automatiquement le code sémantique du mot s (m2). Les mots courants peuvent, s’ils ne sont pas traités comme indiqué plus haut, être traités de cette manière.
- Possibilité 3: (en violet sur le schéma) Le code visuel d’un groupe de mots peut être activé automatiquement v(gm). Ce code active automatiquement le code phonologique du groupe de mot p (gm), lequel active à son tour automatiquement le code sémantique du groupe de mot (GMs). Ce type de traitement est propre aux mots composés tels que « tire-bouchon » ou « pince à linge ».
- Possibilité 4 : (en vert sur le schéma) Le stimulus graphique est automatiquement codé en deux patrons orthographiques (po4 et po5). Ces deux codes sont alors combinés, avec l’aide de l’attention (indiquée par la ligne en pointillés), en un code-mot phonologique p (m4), lequel active avec l’aide de l’attention le code épisodique C1. L’attention portée permet alors d’activer le code sémantique s (m4). Le mot « digicode » peut faire l’objet d’un tel traitement.
- Possibilité 5 : (en orange sur le schéma) Le stimulus graphique est codé avec l’aide de l’attention en un code mot visuel. L’attention active ce code afin d’engendrer un code épisodique e2. Le code sémantique du mot est activé lorsque l’attention se porte sur e2. Ce traitement est celui pouvant être par exemple appliqué à un mot étranger au sein d’un texte.
Si la répétition permet l’automatisation de certains processus, elle participe également de l’unification d’unités de « bas niveaux » en unités de « hauts niveaux ». En effet, avec la pratique, le lecteur abandonne la lecture « mot à mot » et traite des unités plus larges pouvant être de l’ordre des groupes de mots, voire des syntagmes.
En résumé, les modèles présentés dans cette section mettent en exergue l’influence que peuvent exercer en lecture des facteurs purement linguistiques tels que la fréquence, des facteurs psycholinguistiques tels que prédictibilité ou encore des facteurs plus purement psychologiques tels que l’attention.
![]()
[1] Des expériences ont montré que des patients anarthriques de naissance ou devenus anarthriques (c’est-à-dire ayant des problèmes de programmation des gestes moteurs de la parole), présentaient les mêmes effets de longueur du mot ou de similarité phonologique que les sujets normaux. Le terme de boucle phonologique est dont préférable à celui de boucle articulatoire dès lors que ce dernier semble indiquer une interaction directe du langage or, notre dernière remarque au sujet des patients anarthriques montre bien que le langage intérieur ne dépend du langage extérieur ni pour son développement, ni pour son fonctionnement.